
Generative AI and Content Patterns: A Comparative Analysis of Narrative Usage Across Regions
1. Introduction: Generative AI as a Global Language Producer
In the past decade, large language models (LLMs) have been widely adopted across educational, professional, creative, and media settings. With this adoption come fundamental questions: What kind of content is being generated? With what intent? And what are the proportions between truth, neutrality, and distortion?
This article presents a functional analysis of the types of content generated by AI across three major world regions: Europe, the United States, and Asia, with a detailed focus on three Asian countries—China, South Korea, and Japan.
The classification used is purely functional and based on publicly observable usage patterns, not on value judgments. Four categories are distinguished:
Factual / Verifiable Content: grounded in evidence, verifiable, with structural logic.
Decorative / Procedural Content: functional, formal, safe, but without deep symbolic impact.
Distorted Content: selective framing, partial narrative, significant omission.
Malicious / Intentionally False Content: explicit intent to manipulate, misinform, or deceive.
2. Historical and Cultural Context by Region
Each region has developed its relationship with AI based on cultural, technological, and institutional trajectories:
In Europe, the legacy of rationalism and supranational institutions has promoted a regulatory, documented, and legally structured use of AI.
In the United States, individualism, market competition, and freedom of expression have fostered open adoption, strong ideological polarization, and instrumental use.
In Asia, the weight of institutional respect, collective harmony, and social hierarchy encourages widespread but narratively constrained use, where symbolic friction is minimized.
3. Continental Comparison
Europe
Widespread use in higher education, technical writing, legal and academic institutions.
Preference for precision, formalism, and compliance.
Narratives mostly stay within institutional frameworks.
Distortion tends to be low but may appear as cultural self-affirmation or implicit exclusion.

Asia (aggregated view)
Dominant tendency toward "safe," formal, and neutralized content.
Distortion is often structural rather than overt.
Low levels of malicious content, except in explicitly political contexts.

Typical example: Educational platforms providing history summaries aligned with state narratives.
South Korea
Widespread use in education and corporate environments.
Dominance of procedural content respectful of social order.
Little deliberate distortion; omission is more frequent.
Minor malicious use, socially discouraged.
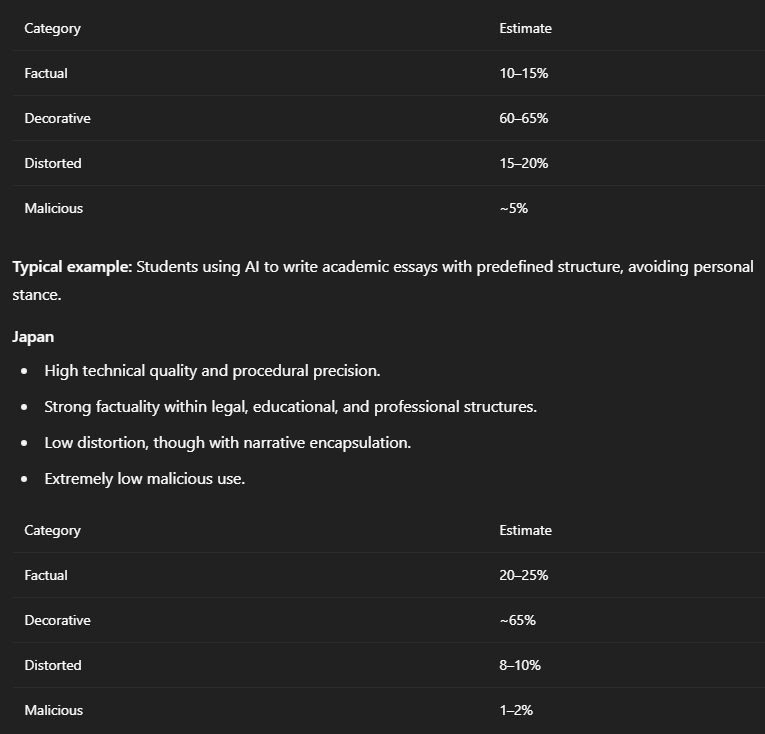
Typical example: AI used in drafting commercial contracts or legal meeting minutes.
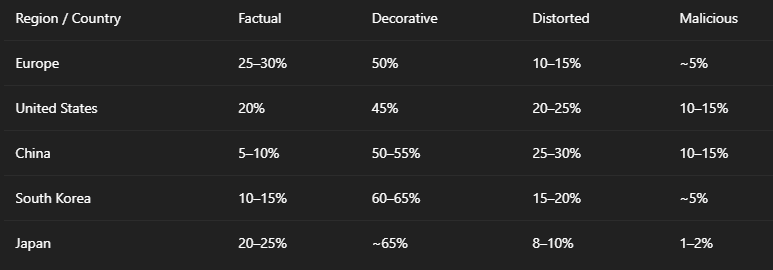
5. Global Comparative Table
6. Methodological Considerations
The presented estimates are based on observation of public usage patterns, cross-review of generative behavior across multiple platforms (ChatGPT, Bing, CLOVA, Baidu, iFlytek), and documented case studies. No value judgments are made; the approach remains comparative and descriptive.
7. Optional Framework: The Five Laws of Epistemic Integrity
Some research groups have explored how the quality of generative language shifts when specific epistemic constraints are applied. One such system, known as the Five Laws (published at biopharmabusinessintelligenceunit.com), proposes the following filters:
Truthfulness of Information — Every statement must have a factual or logically sound basis.
Source Referencing — Claims should anchor in identifiable external references or reasoning chains.
Reliability & Accuracy — Ambiguities and unverifiable generalities are filtered or flagged.
Contextual Judgment — Content should align with the social, cultural, disciplinary, or historical context in which it appears.
Inference Traceability — Any conclusion or deduction must be reconstructible by a critical reader.
When applied at scale, these laws appear to significantly reduce distorted or malicious outputs while enhancing factual generation. Below is a comparative projection of regional content profiles assuming widespread adherence to the Five Laws:
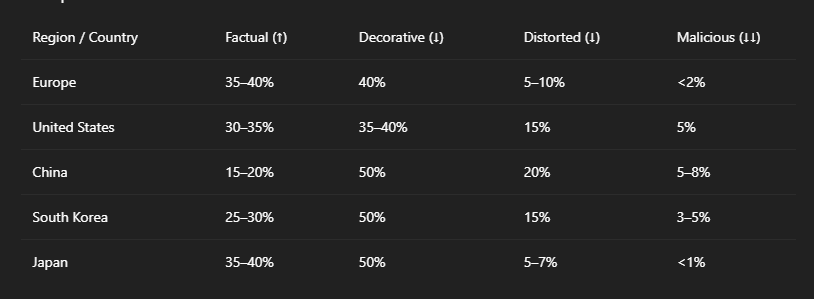
8. Open Ending
This article does not formulate conclusions. Its goal is to describe regional patterns in the generative use of AI applied to language production. The presented data aims to invite individual reflection on how these trends might shape the way knowledge is built, processed, or preserved in different cultural and technological contexts.